How It Works
The architecture behind swarm intelligence prediction

Why swarm prediction?
Most AI prediction tools work the same way: you ask a single language model a question and it gives you one answer. The problem is that a single model carries a single set of biases, blind spots, and reasoning habits. It has no way to challenge itself. If it starts down the wrong path, there is nothing to pull it back.
This engine takes a different approach. Instead of asking one model once, it creates a population of AI agents, each with a different perspective, and makes them debate. Agents argue, challenge each other, shift their positions when they encounter better evidence, and eventually settle into a consensus. The final prediction comes from that consensus, not from any single agent.
The idea is borrowed from ensemble methods in machine learning (where many weak learners outperform one strong learner) and from prediction markets (where aggregated independent judgments beat individual expert forecasts). The difference is that this system makes the reasoning process visible. You can read the debate, see who changed their mind and why, and judge for yourself whether the conclusion is sound.
The problem with single-model predictions
Language models are trained on massive datasets, but that training creates systematic tendencies. A model might consistently overweight recent events, avoid contrarian positions, or default to hedging language that sounds authoritative but says very little. When you ask a model "Will X happen?", the answer depends heavily on how the question is framed, what context is provided, and the model's implicit priors.
There is no self-correction mechanism. If you ask the same model the same question ten times, you get ten variations of the same answer. The responses look diverse on the surface but share the same underlying reasoning structure. This is not diversity of thought. It is diversity of phrasing.
This engine solves that by forcing genuine disagreement. Each agent is constructed with a different cognitive profile: different areas of expertise, different risk tolerances, different reasoning styles. Some agents are analytically rigorous. Some are intuition-driven. Some are deliberately contrarian. When these agents engage with each other, blind spots get exposed and weak arguments get challenged.
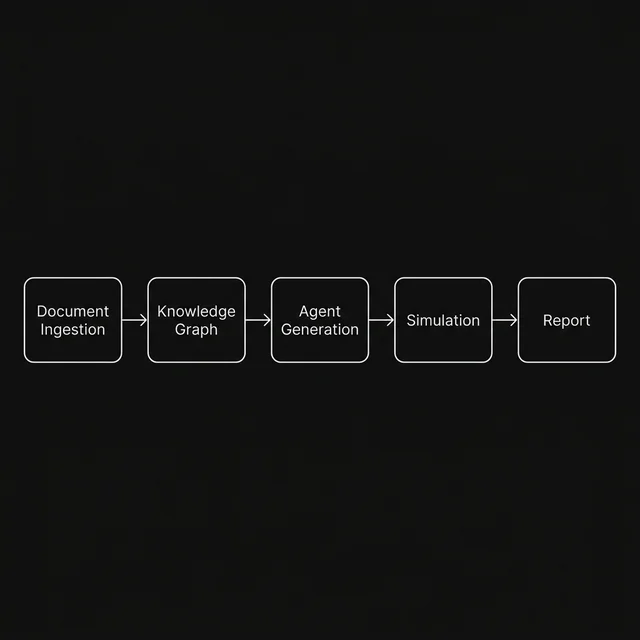
The prediction pipeline
Every prediction runs through five stages, each building on the output of the previous one. The pipeline is designed so that the quality of each stage compounds. A better knowledge graph leads to more relevant agents, which leads to a richer debate, which leads to a better report.
Document ingestion
Your source files are parsed into a clean text corpus with structure preserved.
Knowledge graph extraction
Entities, relationships, and causal structures are identified and linked into a typed graph.
Agent generation
Diverse cognitive personas are created, each with unique expertise, reasoning style, and risk posture.
Multi-round simulation
Agents debate across multiple rounds, posting analyses, challenging each other, and shifting positions.
Consensus report
The full debate transcript is analysed to produce a structured prediction with confidence bounds.
Stage 1: Document ingestion
The engine accepts input in several formats: uploaded files (PDF, Markdown, plain text), pasted text, or a URL. The input is normalised into a clean text corpus with metadata preserved where possible (headings, structure, source attribution).
This stage is intentionally simple. The goal is to get your data into a form that the next stage can work with. There is no summarisation or lossy compression here. The full text is preserved because the agents need access to specifics, not summaries.
Stage 2: Knowledge graph extraction
Before any agents are created, the engine builds a knowledge graph from your input data. This is the factual substrate that all agents share. The process has two parts: ontology detection and entity extraction.
Ontology detection identifies the types of things that matter in your data. If you upload a financial report, the ontology might include companies, metrics, market events, and regulatory actions. If you upload a geopolitical analysis, it might include nations, leaders, treaties, and conflicts. The ontology is not pre-defined. It is inferred from the data itself.
Entity extractionthen populates that ontology with specific instances. Each entity gets a type, a description, and a set of relationships to other entities. The relationships are directional and typed: "Company A acquired Company B", "Policy X was enacted in response to Event Y". These relationships form the edges of the knowledge graph.
The knowledge graph serves two purposes. First, it gives agents a shared factual foundation so they argue about interpretation rather than facts. Second, it determines what kinds of agents get created in the next stage.
Stage 3: Agent generation
Each agent in the swarm is not a generic chatbot. It is a purpose-built cognitive persona with several properties that shape how it thinks:
- Expertise domain. Drawn from the knowledge graph's entity types. An agent specialising in financial metrics will focus on different aspects of the data than one specialising in regulatory risk.
- Reasoning style. Some agents reason analytically, working through evidence step by step. Others reason by analogy, drawing on historical parallels. Others are synthesis-oriented, looking for patterns across domains.
- Risk posture. Conservative agents give more weight to downside scenarios. Aggressive agents focus on upside potential. This ensures that the debate explores the full probability space rather than clustering around the median.
- Initial stance. Every agent enters the simulation with a starting position on the prediction question. This position is informed by their profile but is explicitly subject to change during the debate.
- Persuadability. How much evidence it takes for an agent to change its mind. Low-persuadability agents act as anchors, forcing the debate to produce strong evidence before consensus can shift. High-persuadability agents respond quickly to new arguments, acting as early signals for emerging consensus.
The number of agents scales with the chosen simulation depth. A quick run uses 10 agents. A maximum-depth run uses 100. The profiles are generated to maximise diversity across all five dimensions listed above.
Stage 4: Multi-round simulation
This is where the prediction actually happens. The simulation runs in discrete rounds. In each round, a subset of agents are selected to participate. Each participating agent can do one of three things:
- Post an original analysis. The agent reads the knowledge graph, considers the prediction question through its cognitive lens, and writes a position statement with supporting reasoning.
- Reply to another agent. The agent reads a previous post and either supports it with additional evidence, challenges it with counter-arguments, or offers a synthesis that reconciles competing views.
- Shift its stance. If an agent encounters an argument compelling enough to overcome its persuadability threshold, it changes its position. The shift is logged with the old stance, the new stance, the triggering argument, and the agent's stated reason for changing. This creates an auditable trail of how opinion evolved.
The simulation does not have a pre-determined outcome. Agents make independent decisions based on their profiles and the arguments they encounter. Consensus can emerge quickly if the evidence strongly favours one outcome, or the debate can remain contested through the final round if the question is genuinely uncertain.
Depth presets:
- Quick - 10 agents, 4 rounds, about 1 minute
- Balanced - 30 agents, 8 rounds, about 3 minutes
- Deep - 50 agents, 12 rounds, about 8 minutes
- Maximum - 100 agents, 16 rounds, about 15 minutes
Stage 5: Consensus report
After the simulation finishes, a dedicated report agent reads the complete debate transcript and generates a structured prediction report. This agent does not participate in the debate itself. It acts as an impartial analyst of the debate's outcome.
The report includes:
- The majority position with the key arguments that support it
- Minority positions and why they persisted despite counter-arguments
- A list of stance shifts showing which agents changed their minds and why
- Points of agreement that held across all agents regardless of profile
- Unresolved disagreements where agents could not reach consensus
- Risk factors and edge cases identified by contrarian agents
- A final probabilistic assessment with confidence bounds
Follow-up questions
After the report is generated, you can ask follow-up questions about the simulation. The system has access to the full debate transcript, all agent profiles, the knowledge graph, and the final report. You can ask things like "Which agents disagreed the most?", "What would change the prediction?", or "What assumptions is the majority position relying on?".
This turns the prediction from a one-shot output into an interactive analysis session. You can drill into the reasoning, challenge the assumptions, and use the system as a thinking partner rather than an oracle.
Security and privacy
The engine operates on a Bring Your Own Key model. You provide your own API key from any supported provider. The key is stored only in your browser's local storage. When you start a prediction, the key is sent over HTTPS to the backend, used for a single request, and then deleted from server memory. It is never written to disk, never logged, and never shared with any third party.
Your input data is processed in memory during the prediction run. Nothing is persisted after the process completes. There is no database of past predictions, no user accounts, and no tracking. Each prediction is a self-contained, stateless operation.
Supported LLM providers
The engine supports 8 LLM providers through the BYOK system. You can use whichever provider you already have an API key for:
Technology stack
Limitations and honest caveats
This system is a tool for structured thinking, not an oracle. There are real limitations worth understanding:
- Garbage in, garbage out. The quality of the prediction depends heavily on the quality and relevance of the input data. Vague or insufficient data produces vague predictions.
- LLM constraints apply. The agents are powered by language models, which means they inherit the training data cutoffs, knowledge gaps, and reasoning limitations of those models.
- Not calibrated on real outcomes. Unlike prediction markets, which are calibrated by real money and real outcomes, this system has no feedback mechanism. The confidence percentages should be treated as relative indicators, not absolute probabilities.
- Cost scales with depth. Each agent makes LLM calls. A maximum-depth run with 100 agents across 16 rounds can consume significant API credits. The depth presets exist to give you control over this tradeoff.